Rancher Monitoring
Introducción
El monitoreo de recursos de nuestras aplicativos y nuestro cluster en general es una parte critica a la hora de administrador un cluster de rke2, con la informacion que podemos obtener del monitoreo podemos decidir si le quitamos recursos a nuestro aplicativo, si podemos colocar un nuevo aplicativo o que nodos estan con mayor carga, etc.
Laboratorio: Instalacion y prueba de componentes de rancher monitoring.
Objetivo
En la presente guía se instalarán las herramientas de monitoreo que nos provee rancher en forma de un solo chart, el que se conoce como rancher monitoring el cual nos incluye, grafana, prometheus y alert manager.
Objetivos
Objetivo General: - Conocer una de las soluciones para monitoreo de aplicaciones que nos provee rancher e implementarla.
Antes de comenzar
- Contar con el acceso al ambiente de laboratorio
Inicio de laboratorio
- Asegurarse de estar en el servidor
bastioncon el usuariostudentExportamos la variable de entorno para acceder al cluster.student@lab-0-bastion:~>export KUBECONFIG=/home/student/rke2_conn/cluster1/cluster1_kubeconfig.yaml - Vamos a ingresar a Rancher en el cluster 1 y vamos a buscar en la parte de apps y charts Rancher monitoring.

3. Vamos a instarlo con los siguients valores en la parte de prometheus.
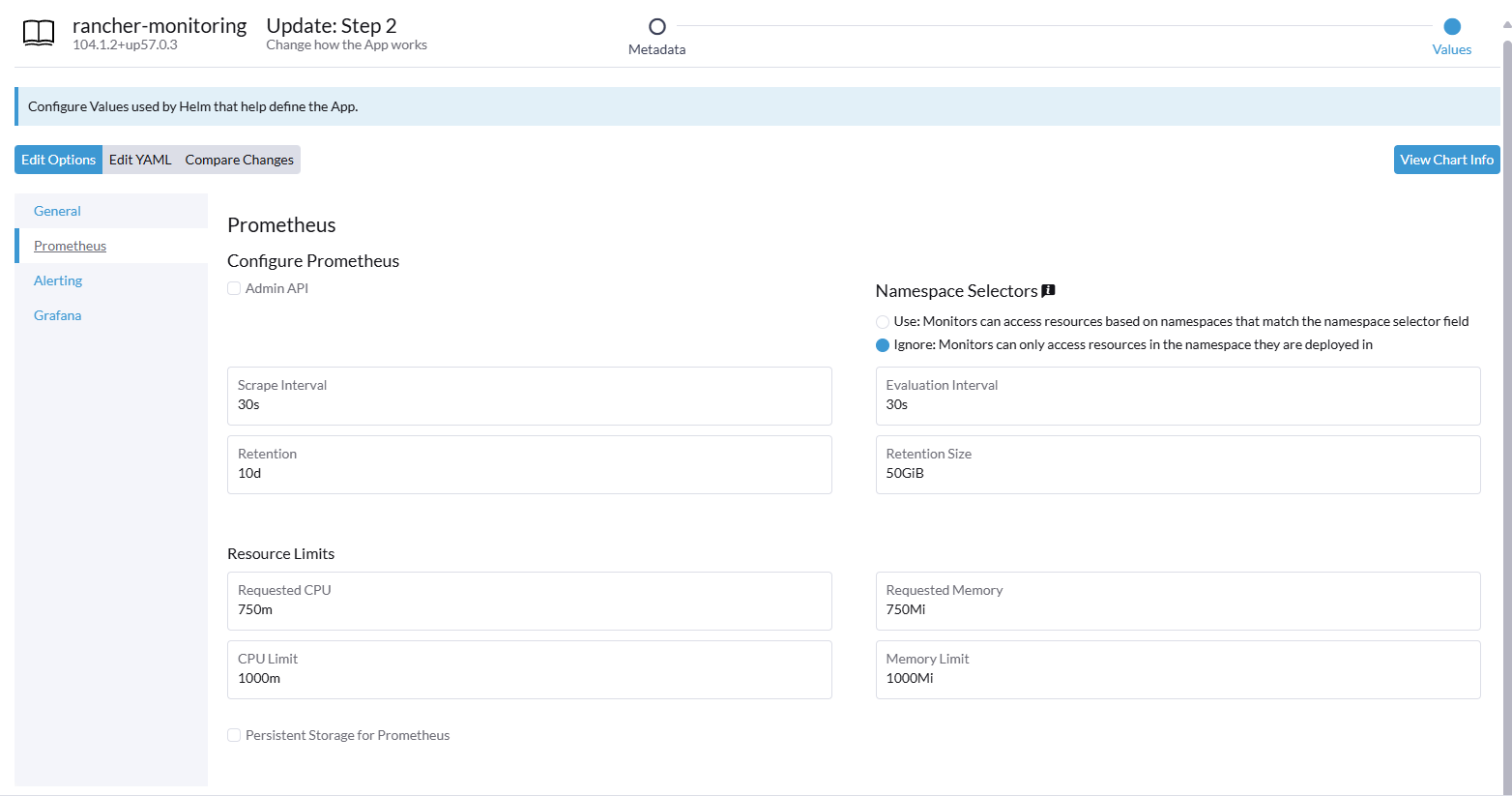 Lo demas lo dejamos por defecto.
Lo demas lo dejamos por defecto.
4. Esperamos que finalize la instalacion.
5. Una vez finalice vamos a observa que en el menu del lado izquierdo de rancher hay una nueva opcion llamada monitoring.
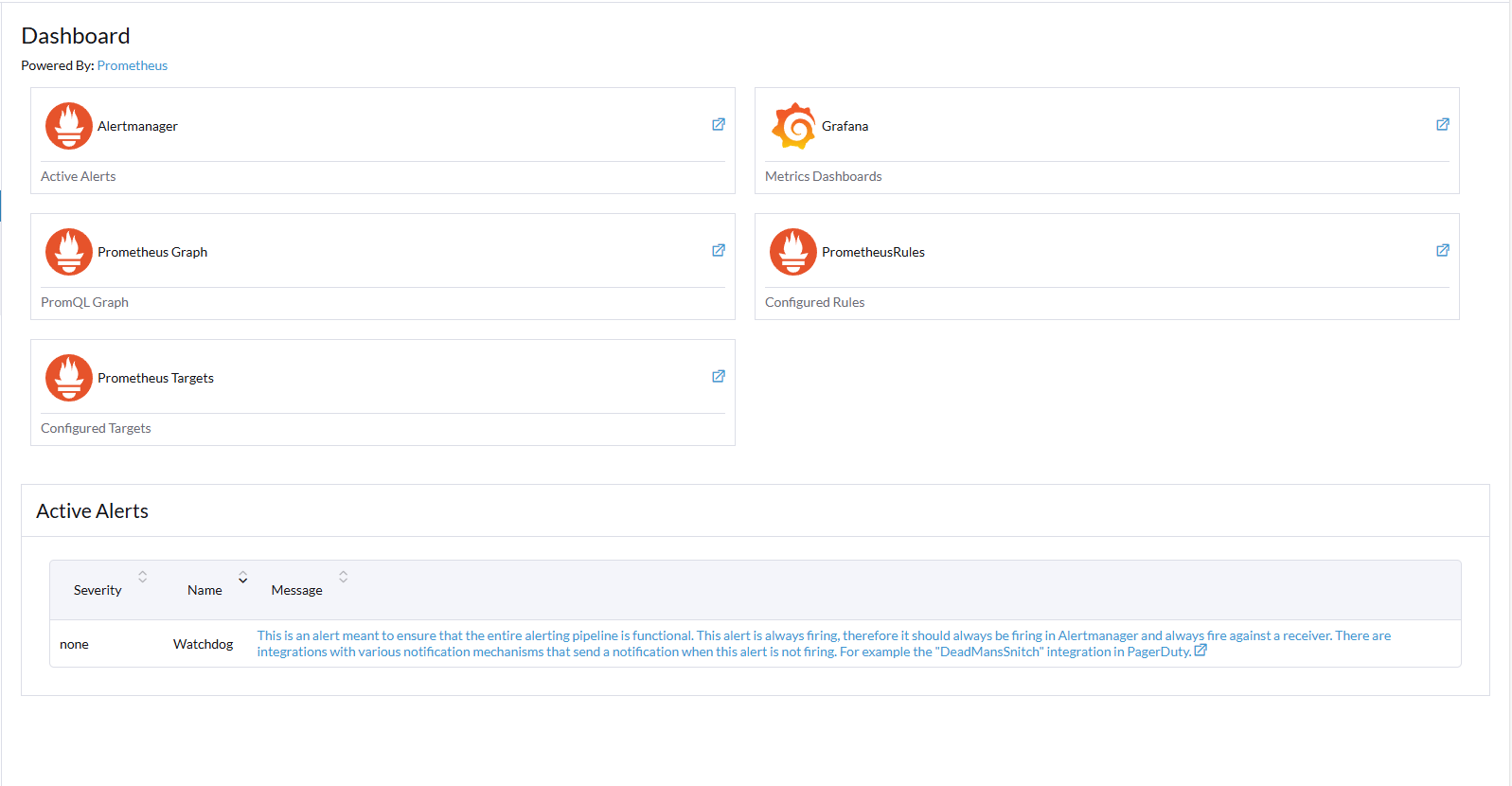
Vamos a hablar un poco de cada una de estas opciones.
-
Primero prometheus que es la base del monitoreo, prometheus se compone de varios elementos, primeramente prometheus target que es de donde prometheus saca sus metricas, estas metricas son expuestas por los aplicativos y prometheus se encarga solamente de tomarlas, luego tenemos las prometheusrules que son reglas que definen las alertas del cluster, por ejemplo puede que exista una regla para que si un nodo no da metricas por 5 minutos se alerte porque puede que este abajo y finalmente la parte de prometheusgraph que nos permite hacer graficos con las metricas que tenemos.
-
El siguiente componente es grafana, el cual es basicamente una representacion grafica de las metricas de prometheus, por si solas las metricas no significan nada pero grafana nos permite graficar para saber consumo promedio en un tiempo establecid por ejemplo o en un nodo en especifico, hay graficos por defecto de prometheus asi como graficos de terceros que se pueden importar y finalmente se pueden crear graficos personalizados.
- El ultimo componente es alert manager, alert manager nos brinda las alertas en base a las reglas de prometheus y nos las muestra en el cluster como se ve en la foto anterior. Estas alertas de igual manera se puede configurar por criticidad y mas importantes se pueden enviar a un servicio fuera del cluster como puede ser un canal de slack o teams o un correo electronico.
Siguiendo con la guia
6. Vamos a entrar a la parte de grafana, se deberia de mostrar la interfaz asi.
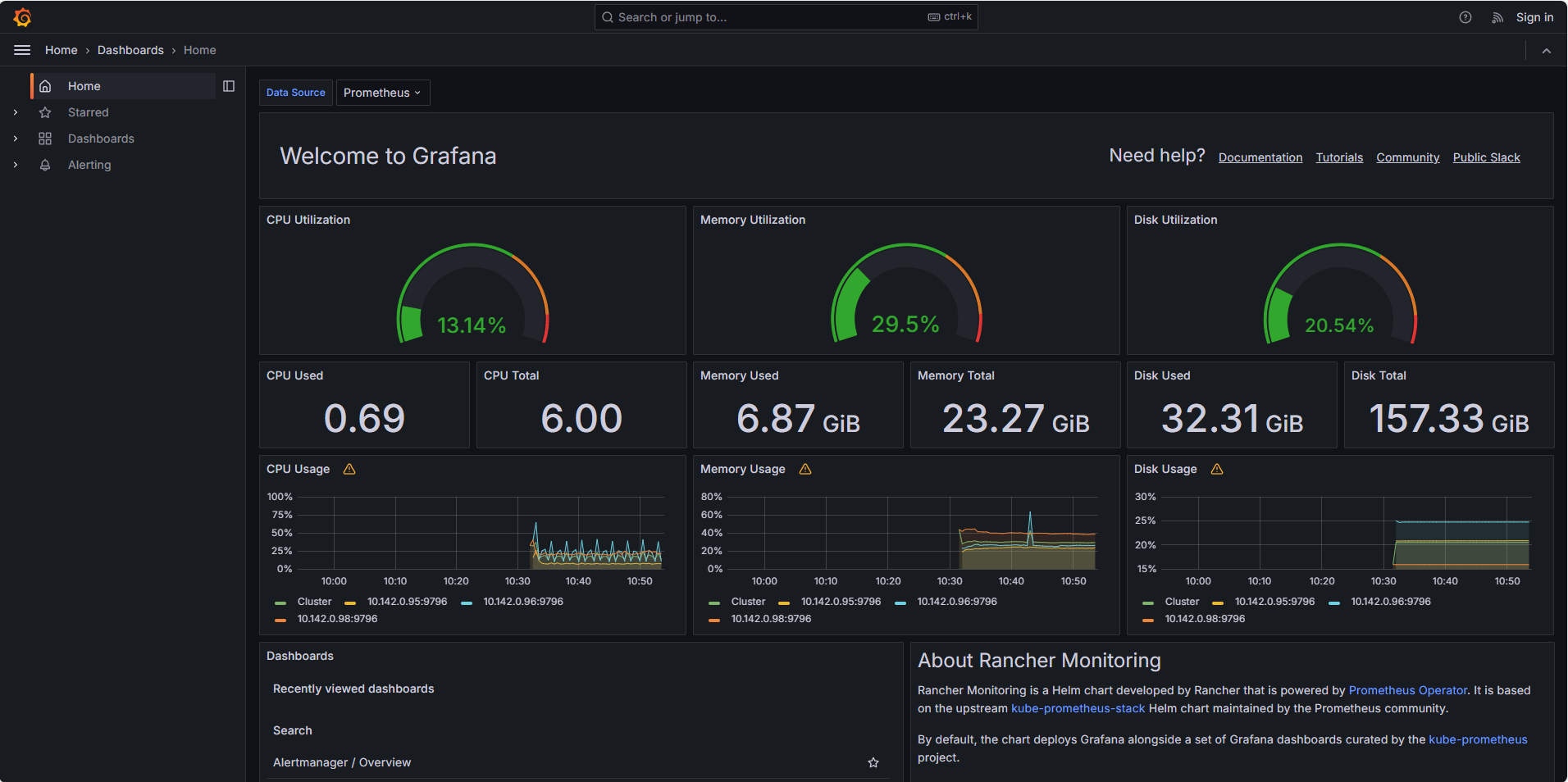 Aqui podemos ver los graficos por defecto que son un resumen del uso de recursos en el cluster para los recursos mas importantes que son cpu, memoria y disco.
Aqui podemos ver los graficos por defecto que son un resumen del uso de recursos en el cluster para los recursos mas importantes que son cpu, memoria y disco.
7. Vamos a volver a nuestro bastion y vamos a crear una nueva carga de trabajo para aumentar el uso de recursos en el cluster y ver como cambia en grafana.
Vamos a crear un nuevo namespace y un aplicativo al que le vamos a mandar carga
kubectl create ns recursos
kubectl apply -f https://k8s.io/examples/application/php-apache.yaml -n recursos
kubectl run -i -n recursos --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
8. Una vez pasen los 5 minutos vamos a entrar a grafana nuevamente y vamos a observar que el consumo se elevado en todas las metricas y vamos a ver unos picos en las graficas mas pequeñas, que nos dicen que hubo un pod que estaba consumiendo mas que los demas.
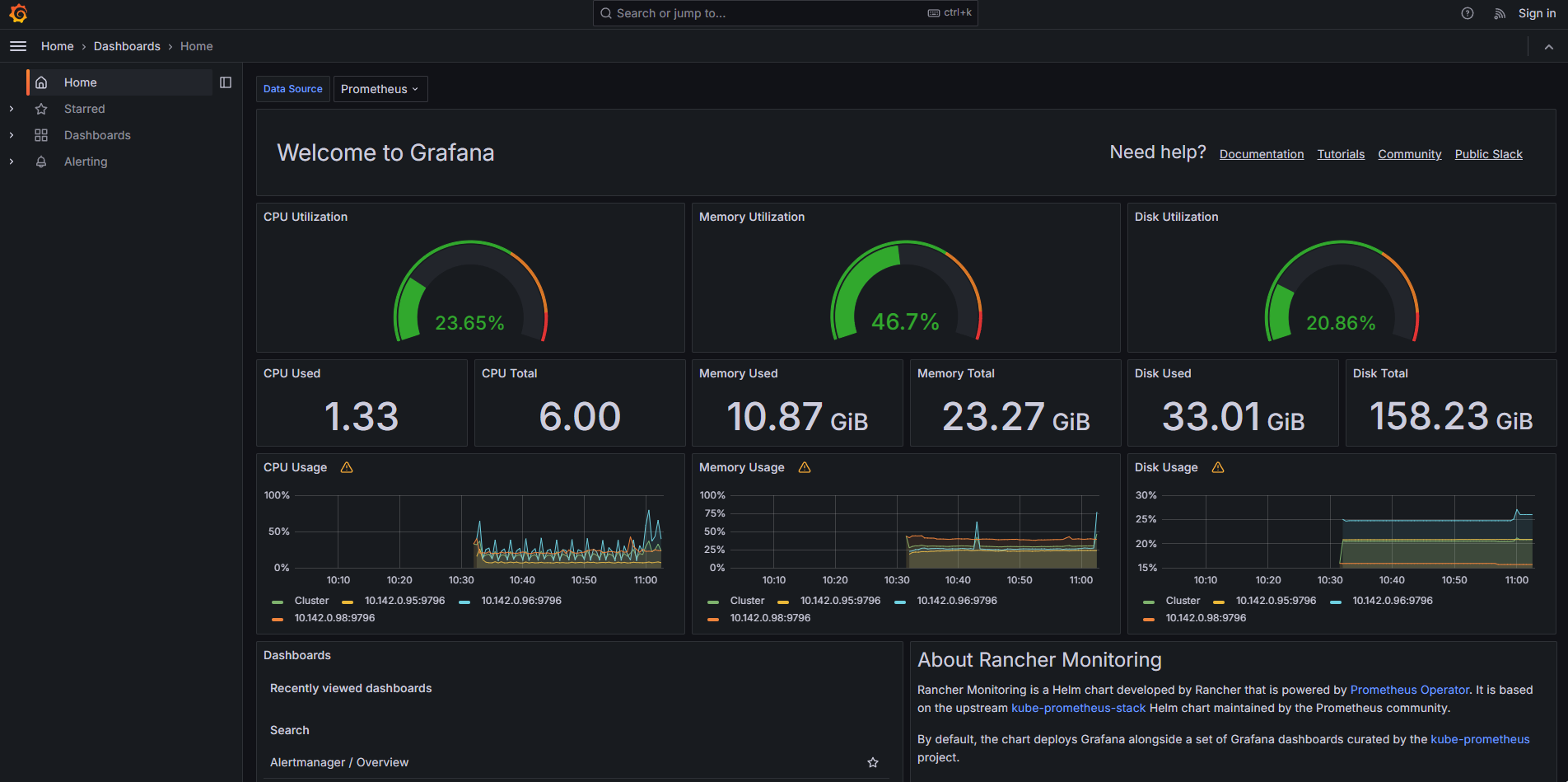
9. Finalmente vamos a limpiar el ambiente
kubectl delete ns recursos